

Artificial intelligence may look intelligent on the surface, but every modern AI system is built on one core foundation: data. Data determines what a model can learn, how accurately it can respond, how well it adapts to new situations, and where its limitations begin. If you want to understand how AI really works, you first need to understand how AI uses data. From large language models and image generators to speech systems and multimodal assistants, every AI capability begins with the same process: raw information is transformed into patterns, those patterns are learned during training, and that learning shapes how the model responds later. In this guide, we break down that full process step by step, from datasets and tokenization to parameters, training, inference, and model behavior. The goal is simple: to show how data becomes intelligence, and why data quality remains one of the most important drivers of modern AI performance.
Table of Contents
ToggleThe AI Data Pipeline (Simple Overview)
Artificial intelligence does not process information in a single step. Instead, it follows a structured pipeline that transforms raw data into intelligent behavior. Understanding this pipeline is essential if you want to move beyond surface-level explanations and truly grasp how AI systems operate.
At a high level, every modern AI model follows the same core process:
Data → Tokens → Training → Parameters → Inference → Output
Each stage reduces complexity while increasing structure, allowing the model to convert raw information into usable predictions.
Data
Text, images, audio, code, and multimodal inputs form the foundation of what the model can learn.
Tokens
Raw information is converted into tokens so the model can process patterns mathematically.
Training
The model predicts patterns and adjusts itself continuously to reduce errors.
Parameters
Learned relationships are stored as numerical weights inside the model.
Inference
The model applies learned patterns to new input in real time.
Output
The final result is generated step by step based on learned probabilities.
Data
Everything begins with data. This includes text, images, audio, code, and multimodal inputs. The scale, quality, and diversity of this data determine what the model can learn and how well it performs.
Tokens
Before a model can process information, data must be converted into tokens. These are small units of text or signal that the model can interpret mathematically. Tokenization is what allows AI systems to handle language, structure meaning, and detect patterns across sequences. If you want to understand this step in more depth, see how transformers process tokens and context in How Transformers Work.
Training
During training, the model learns by predicting patterns within the data. It continuously compares its predictions with actual outcomes and adjusts itself to reduce errors. This iterative process is what enables models to improve over time. For a broader explanation of this learning process, see How Artificial Intelligence Works.
Parameters
The learned patterns are stored inside the model as parameters. These numerical values represent relationships between tokens, concepts, and structures. Over time, they encode everything the model has learned, from grammar and semantics to reasoning patterns. For a deeper breakdown, see Neural Networks Explained.
Inference
Once training is complete, the model enters the inference phase. This is where it applies learned patterns to new input, generating responses, predictions, or outputs in real time.
Output
The final result is generated step by step, based on probabilities learned during training. What appears as intelligence is actually the result of structured pattern recognition operating at scale.
This pipeline explains how AI transforms raw information into structured behavior. Each stage plays a critical role in shaping how a model interprets input, generates output, and performs in real-world applications.
Why Data Is the Real Foundation of AI
Artificial intelligence is often described as a breakthrough in algorithms, but in reality, modern AI is driven far more by data than by model architecture. While improvements in neural networks and transformer designs have enabled progress, the biggest performance gains come from better data.
AI does not understand the world. It learns patterns from the data it is trained on. This means that everything a model can do — and everything it fails to do — is a direct reflection of its training data.
The relationship is simple:
Better data → more reliable models
Poor data → unreliable outputs
This applies across all AI systems, from language models and image generators to recommendation engines and predictive analytics.
AI learns patterns, not facts
AI systems do not store knowledge in the way humans do. Instead, they learn statistical relationships between inputs and outputs. For example, a model does not “know” what a concept is — it learns how that concept behaves across thousands or millions of examples. This is why AI can generate highly convincing responses while still producing incorrect or misleading information.
Data quality defines model behavior
The structure and quality of a dataset directly influence how a model behaves. If the data is incomplete, inconsistent, or biased, those characteristics will appear in the model’s outputs. This is one of the core reasons why hallucinations and reliability issues occur, as explored in AI Risks Explained.
Scale alone is not enough
Modern AI systems are trained on enormous datasets, including trillions of words, billions of images, and vast amounts of code and audio. However, scale alone does not guarantee better performance. High-quality, well-distributed, and diverse data is far more valuable than simply increasing volume.
This is why leading AI systems focus on:
- curated datasets
- filtered and cleaned data
- synthetic data generation
- reinforcement learning from human feedback
These techniques improve signal quality rather than just increasing size.
Data is now the main bottleneck in AI
In the early stages of AI development, progress was limited by compute power and model design. Today, those constraints are increasingly being solved. The new bottleneck is data.
High-quality data is:
- expensive to collect
- difficult to clean
- hard to scale responsibly
- often restricted by legal and ethical constraints
This shift explains why companies invest heavily in data pipelines, data labeling, and synthetic data generation.
From data to intelligence
At its core, AI does not become powerful because it is “smart.” It becomes powerful because it has learned from vast, structured, and well-optimized data. The model’s behavior is simply the result of compressed patterns extracted during training, a process explained in more detail in How Artificial Intelligence Works.
Understanding this changes how you think about AI. Instead of asking how intelligent a model is, the better question becomes:
How good is the data behind it?
What Is a Dataset? (Simple Definition)
A dataset is a structured collection of examples that an AI model uses to learn patterns. Each example contains information that helps the model understand relationships, whether in language, images, audio, or code.
In simple terms, a dataset defines what an AI model can learn — and what it cannot.
Different types of AI systems rely on different kinds of datasets, depending on the task they are designed to perform.

Text datasets (language models)
Large language models are trained on vast collections of text data. This includes books, articles, academic papers, documentation, and curated internet sources. These datasets allow models to learn grammar, context, reasoning patterns, and semantic relationships. If you want to understand how these systems use text at scale, see LLM Explained.
Image datasets (computer vision)
Image-based AI systems learn from labeled and unlabeled image datasets. These include well-known datasets such as ImageNet, COCO, and large-scale image-text datasets like LAION. Models learn to recognize objects, patterns, and visual structures by analyzing millions or billions of images.
Audio datasets (speech and sound)
Speech recognition and audio models are trained on large collections of spoken language and sound recordings. These datasets include podcasts, interviews, lectures, and multilingual speech corpora. They enable models to convert speech to text, detect tone, and process audio signals.
Code datasets (software understanding)
AI systems trained on code use large repositories of programming data. This includes open-source projects, documentation, and developer discussions. These datasets allow models to understand syntax, generate code, and assist with software development tasks.
Multimodal datasets (next-generation AI)
Modern AI systems increasingly combine multiple data types into a single training process. Multimodal datasets include text, images, audio, video, and other signals, allowing models to understand and generate across different formats.
This is the foundation of advanced systems that can see, hear, read, and generate content in multiple forms, as explored further in How AI Works in Real Life.
From Data to Tokens: How AI Understands Information
AI models cannot read text, images, or audio in their raw form. Before any learning can happen, all input must be converted into a format the model can process mathematically. This is where tokenization begins.
A token is a small unit of information. In language models, tokens are typically pieces of words rather than full words.
For example:
“Artificial intelligence” → “Artificial”, “ intelligence”
“Understanding” → “Under”, “standing”
These tokens allow the model to break down language into manageable components that can be analyzed, compared, and predicted.
Why tokenization matters
Tokenization is not just a technical step — it directly affects how a model performs. The way text is split into tokens influences how efficiently the model can process information and how well it can understand context.
Tokenization impacts:
- model speed
- API cost (pricing is based on tokens)
- memory usage
- context window limits
- ability to handle rare or complex words
A poorly designed tokenization system can limit performance, even if the underlying model is powerful.
Tokens are the language of transformers
Once data is converted into tokens, it enters the transformer architecture. Transformers process sequences of tokens using attention mechanisms, allowing the model to understand relationships between words, sentences, and concepts across context.
This is where meaning begins to emerge — not from words themselves, but from how tokens relate to each other mathematically. For a deeper explanation of this process, see How Transformers Work.
AI does not see sentences — it sees patterns
Humans read sentences. AI models process token sequences.
What looks like language to us is, for a model, a structured sequence of probabilities. Each token is interpreted based on its relationship to surrounding tokens, not based on inherent meaning.
This is why AI can:
- generate fluent text
- complete sentences
- mimic reasoning
without actually understanding language in a human sense.
The hidden limitation: tokens and context
Tokenization also introduces one of the most important limitations in AI systems: context windows. Because models process input as token sequences, they can only consider a limited number of tokens at once.
This limitation affects:
- long conversations
- document analysis
- multi-step reasoning
We’ll explore this in more detail later in the section on context windows.
Parameters: How AI Stores Patterns and Meaning
Once data has been converted into tokens and processed during training, the model needs a way to store what it has learned. This is where parameters come in.
Parameters, often referred to as weights, are numerical values inside a neural network that encode learned patterns. They determine how strongly certain inputs influence the model’s output and how different pieces of information are connected.
In simple terms, parameters are how an AI model “remembers” what it has learned.
What parameters actually represent
AI models do not store facts, rules, or definitions in a traditional sense. Instead, parameters capture statistical relationships between tokens, concepts, and patterns.
For example, parameters help the model understand:
- which words are likely to follow each other
- how tone and sentiment are expressed
- how code structures are formed
- how visual features relate to objects
These relationships are distributed across millions or billions of parameters, rather than stored in a single location.
Scale: from millions to trillions
Modern AI systems operate at massive scale.
Examples:
- smaller models: millions to billions of parameters
- advanced models: tens or hundreds of billions
- frontier models: approaching or exceeding trillion-parameter scale
More parameters allow a model to capture more complex relationships, but scale alone does not guarantee better performance.
Why more parameters ≠ better intelligence
While larger models can represent more patterns, their performance still depends heavily on data quality and training efficiency.
Key factors that matter more than raw size:
- data quality and diversity
- training methodology
- architecture optimization
- alignment and fine-tuning
This is why smaller, well-trained models can sometimes outperform larger but poorly trained ones.
Parameters are compressed knowledge
A useful way to think about parameters is as compressed knowledge.
Instead of storing entire documents or images, the model compresses patterns from its training data into numerical form. This compression allows it to generalize — to produce new outputs that were never explicitly seen during training.
This is also why AI can generate original text, code, or images: it is not retrieving data, but reconstructing patterns.
From tokens to meaning
Tokens provide the structure, but parameters provide the interpretation.
Without parameters, tokens are just sequences. With parameters, those sequences become meaningful patterns that can be used to generate coherent responses.
This layer — where patterns are stored and applied — is what gives AI systems their apparent intelligence, as explained in more detail in Neural Networks Explained and expanded further in Deep Learning Explained.
How AI Training Actually Works
AI training is the process where a model learns patterns from data and converts them into usable behavior. While the underlying mathematics is complex, the core idea is surprisingly simple: the model learns by making predictions and correcting itself.
At its core, training follows a repeating cycle:
Training in one sentence
AI learns by predicting the next token and adjusting itself based on how wrong it was — repeated billions or even trillions of times.
Step 1: The model reads data
The training process begins with massive datasets. These can include text, images, audio, code, or multimodal data. The model processes this data as sequences of tokens.
Step 2: It makes a prediction
For each sequence, the model tries to predict what comes next. In language models, this is usually the next token in a sentence.
Example:
“The future of AI is” → the model predicts the next token.
Step 3: It compares prediction vs reality
The model’s prediction is compared to the actual correct token. The difference between the prediction and the correct answer is called the loss.
Step 4: It updates its parameters
Using optimization techniques such as gradient descent, the model adjusts its parameters to reduce this loss. This is how learning happens.
Step 5: It repeats at scale
This process is repeated across billions of examples, often running on thousands of GPUs over weeks or months. With each iteration, the model becomes better at recognizing patterns and making accurate predictions.
Over time, this simple loop transforms raw data into structured behavior.
From repetition to intelligence
What makes this process powerful is scale. Individually, each prediction is trivial. But when repeated billions of times across diverse data, the model begins to capture complex patterns such as language structure, reasoning steps, visual recognition, and even coding logic.
This is how AI systems move from basic pattern matching to something that appears intelligent.
Training vs understanding
It is important to understand that training does not create true understanding. The model does not “know” facts or concepts. It learns statistical relationships between tokens and patterns.
This is why AI can:
- generate coherent answers
- simulate reasoning
- produce creative output
while still making mistakes or generating incorrect information.
The visual below explains how AI models learn through iterative feedback loops and why their outputs appear intelligent rather than rule-based.
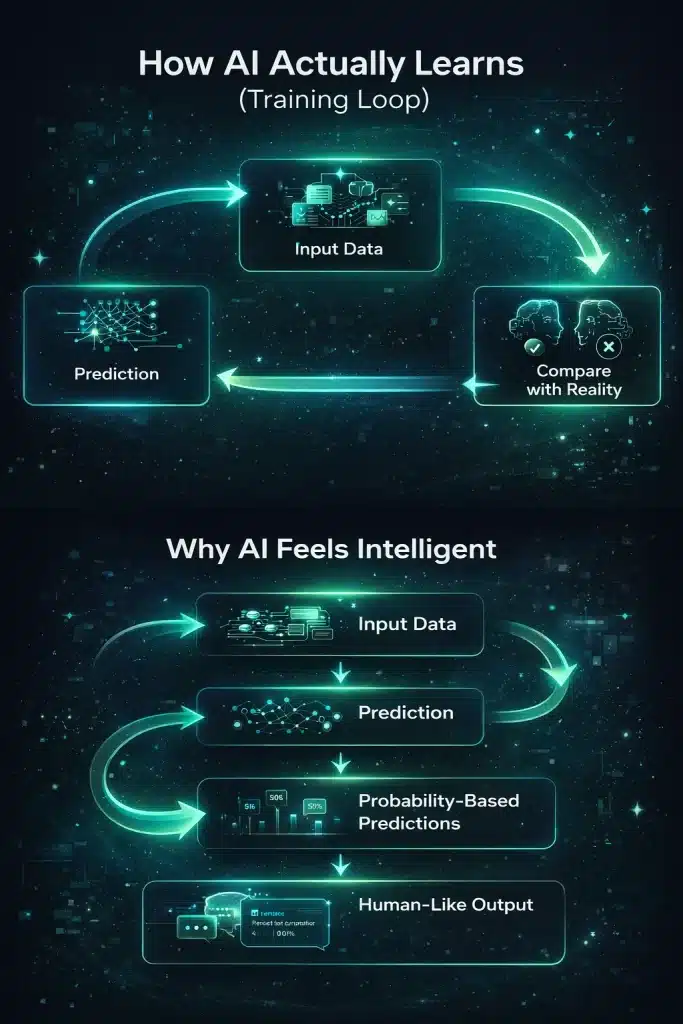
Inference: How AI Uses Data After Training
Once training is complete, the model stops learning and starts applying what it has learned. This phase is called inference.
Inference is the moment where AI becomes useful. It is what happens every time you enter a prompt, upload an image, or interact with an AI system.
While training is slow, expensive, and resource-intensive, inference is designed to be fast and efficient.
What happens during inference
When you interact with an AI model, the same pipeline is activated — but instead of learning, the model is now generating output.
The process looks like this:
Input → Tokenization → Pattern matching → Prediction → Output
Your input is first converted into tokens. These tokens are then processed using the model’s parameters, which contain all the learned patterns from training. The model evaluates probabilities and predicts the most likely next token, repeating this step until a complete response is generated.
Why inference feels intelligent
Inference can feel like real understanding, but it is actually rapid pattern reconstruction.
The model:
- recognizes patterns similar to what it has seen before
- applies learned relationships between tokens
- predicts what should come next based on probability
Because this happens extremely fast and across highly structured patterns, the output appears coherent, contextual, and sometimes even creative.
The difference between training and inference
The key difference is simple:
Training = learning from data
Inference = applying learned patterns
During training, the model updates its parameters. During inference, those parameters remain fixed and are used to generate responses.
This is why AI systems can run efficiently in real-world environments. The heavy computation happens during training, while inference is optimized for speed and scalability.
Why inference matters in real-world AI
Every real-world AI application relies on inference.
This includes:
- chatbots and virtual assistants
- image generation tools
- recommendation systems
- speech recognition
- code generation
Understanding inference helps explain why AI systems can respond instantly, even though they were trained over months on massive infrastructure. For practical examples of how this works in everyday applications, see How AI Works in Real Life.
Context Windows: The Memory Limits of AI Models
AI models do not have memory in the way humans do. Instead, they rely on something called a context window — the amount of information the model can process at once.
A context window is measured in tokens and defines how much input the model can consider when generating a response.
What a context window actually does
When you interact with an AI model, everything you type is converted into tokens and placed inside the context window. The model then processes all those tokens together to generate its response.
If information falls outside this window, the model cannot “see” it anymore.
This means that AI does not remember past conversations unless that information is still inside its current context.
Context size: from limitation to capability
Older AI models were limited to small context windows, often between 512 and 2,048 tokens. This restricted their ability to handle long conversations or complex documents.
Modern models have significantly expanded these limits:
- 32,000 tokens
- 100,000 tokens
- 1 million tokens or more
Some systems extend this even further using retrieval and memory techniques.
Why context windows matter
The size of a context window directly impacts how well a model can perform complex tasks.
Larger context windows improve:
- long-form reasoning
- document analysis
- multi-step problem solving
- conversation continuity
- multimodal understanding
This is one of the key reasons why newer AI systems feel significantly more capable than earlier versions.
The hidden trade-off
While larger context windows increase capability, they also introduce trade-offs:
- higher computational cost
- increased latency
- more complex optimization
This means that simply increasing context size is not always the most efficient solution.
Beyond context: retrieval and memory systems
To overcome these limitations, modern AI systems increasingly rely on retrieval-based approaches. Instead of storing everything in the context window, the model retrieves relevant information when needed.
This approach, often referred to as retrieval-augmented generation (RAG), allows AI systems to:
- access external knowledge
- handle larger datasets
- maintain more accurate responses
This shift is part of a broader evolution in AI architecture, explored further in Future of AI Systems.
Data Quality, Bias & Safety: The Hidden Challenges
AI systems are only as reliable as the data they are trained on. While modern models can generate highly coherent and useful outputs, they also inherit the limitations, biases, and imperfections of their training data.
This makes data quality one of the most critical — and most overlooked — aspects of AI performance.
Bias: patterns become behavior
AI models learn from historical data. If that data contains biases, those biases are reflected in the model’s outputs.
This can affect:
- hiring systems
- financial decision models
- recommendation algorithms
- language generation
Bias in AI is not intentional. It is a direct result of how patterns are distributed in the training data.
Hallucinations: when patterns go wrong
AI models do not verify facts. They generate outputs based on probability.
When the model lacks strong signals in its training data, it may produce responses that sound correct but are factually incorrect. These are often referred to as hallucinations.
This is not a bug in the traditional sense — it is a limitation of probabilistic systems, explored in more detail in AI Risks Explained.
Data quality: the real performance driver
The most advanced AI systems do not rely on raw data alone. They depend on carefully curated, filtered, and structured datasets.
High-quality data typically involves:
- cleaning and filtering
- removing noise and duplication
- balancing distributions
- adding human feedback
- generating synthetic data
Improving data quality often leads to greater performance gains than simply increasing model size.
Copyright and data provenance
As AI systems scale, questions around data ownership and usage have become more important.
Key concerns include:
- whether data was used with permission
- how copyrighted material is handled
- how training data is sourced and documented
These issues are shaping how future AI systems are trained and deployed.
Regulation and data governance
Governments and institutions are increasingly focusing on how AI systems are trained and used.
Frameworks such as the EU AI Act emphasize:
- transparency in training data
- accountability for model behavior
- risk classification of AI systems
- governance of high-impact applications
This reflects a broader shift: AI is no longer just a technical system — it is also a regulatory and societal one.
The Future of AI Data: From Scale to Intelligence
The next phase of artificial intelligence will not be defined by larger models alone, but by how data is collected, structured, and used.
For years, AI progress was driven by scale: more data, more compute, more parameters. While this approach unlocked major breakthroughs, it is now reaching practical and economic limits.
The future of AI is shifting toward smarter data, not just more data.
From static datasets to dynamic data systems
Traditional AI models are trained on static datasets — large snapshots of information collected at a specific point in time. Once training is complete, the model no longer updates its knowledge.
This approach is now evolving into dynamic systems where models:
- retrieve information in real time
- update knowledge continuously
- interact with external data sources
This shift reduces reliance on memorization and increases adaptability.
The rise of synthetic data
One of the biggest changes in AI development is the use of synthetic data — data generated by AI itself.
Synthetic data allows:
- faster scaling of training data
- controlled data generation
- improved edge-case coverage
- reduced dependency on scarce or sensitive datasets
However, it also introduces new risks, such as feedback loops where models train on their own outputs.
Multimodal data as the new standard
Future AI systems are increasingly trained on multiple data types simultaneously.
Instead of separating text, images, audio, and video, models learn from combined inputs. This enables more natural interaction and broader understanding across domains.
Multimodal data is what allows AI to:
- interpret images and describe them
- understand speech and respond in text
- combine visual and textual reasoning
This evolution is already visible in modern systems and will become the default in future architectures.
Retrieval over memorization
Rather than storing all knowledge inside parameters, AI systems are moving toward retrieval-based architectures.
Instead of memorizing everything, models:
- search external databases
- retrieve relevant information
- generate responses based on real-time data
This approach improves accuracy, reduces hallucinations, and allows models to work with up-to-date information.
Privacy-preserving AI
As data becomes more central to AI, privacy and security are becoming critical challenges.
New approaches include:
- federated learning
- differential privacy
- on-device AI processing
- encrypted computation
These techniques aim to balance performance with data protection, especially in sensitive domains such as healthcare and finance.
Toward adaptive AI systems
The long-term direction of AI is clear: systems that are not only trained once, but continuously adapt.
Future AI systems will:
- combine training with real-time learning
- integrate memory and retrieval
- operate across multiple data types
- interact dynamically with users and environments
This convergence of data, memory, and adaptability is explored further in Future of AI Systems.
How AI Uses Data (Simple Explanation)
AI uses data by converting information into patterns that can be learned, stored, and applied. Instead of understanding data like humans do, AI processes it mathematically and learns relationships through repetition.
The process follows a simple structure:
- Data is collected
AI models are trained on large datasets containing text, images, audio, code, or multimodal inputs. - Data is converted into tokens
Raw information is broken into smaller units that the model can process. - The model learns patterns during training
It predicts outcomes, compares them to real data, and adjusts itself to reduce errors. This learning process is explained in more detail in How Artificial Intelligence Works. - Patterns are stored as parameters
The model compresses learned relationships into numerical values that guide future behavior. - The model applies these patterns during inference
When given new input, the model uses learned patterns to generate responses, predictions, or outputs.
In short, AI does not store knowledge — it learns patterns from data and uses those patterns to produce results.
Key Takeaways
Data is the foundation of all modern AI systems. Everything a model can do — and everything it gets wrong — is shaped by the data it was trained on.
AI does not understand information. It learns patterns by converting data into tokens, training on those patterns, and storing them as parameters.
Training is the process where models learn from data. Inference is where they apply that learning to generate output.
Context windows define how much information a model can process at once, which directly impacts reasoning, memory, and performance.
Data quality matters more than scale. Better, cleaner, and more diverse data leads to more reliable AI systems.
Modern AI is shifting toward retrieval, multimodal data, and adaptive systems, where models rely less on memorization and more on dynamic information.
Frequently Asked Questions
These answers address the most common questions readers have about how AI uses data, how models learn patterns, and why data quality shapes performance.
How does AI use data to learn?
AI learns by identifying patterns in large datasets. During training, the model predicts outcomes, compares them with real data, and adjusts its internal parameters to reduce errors over time.
What is the difference between datasets, tokens, and parameters?
Datasets provide the raw information, tokens convert that information into machine-readable units, and parameters store the learned patterns inside the model.
Why do AI models hallucinate incorrect information?
AI models generate responses based on probability rather than verified truth. When training data is incomplete, noisy, or lacks strong signals, the model can produce answers that sound convincing but are incorrect.
What is tokenization in AI?
Tokenization is the process of breaking data, especially text, into smaller units called tokens. These tokens allow the model to process information mathematically and identify patterns across sequences.
Why is data quality more important than data size?
Large datasets help models learn at scale, but poor-quality data introduces noise, bias, and inconsistency. High-quality, well-structured, and diverse data usually leads to more reliable AI performance than raw volume alone.
What happens after AI training is complete?
After training, the model moves into inference mode. It no longer updates its parameters, but uses the patterns it has already learned to generate responses, predictions, or outputs from new input.
Continue Learning
To deepen your understanding of AI fundamentals, explore:
- What Is Artificial Intelligence? — the full foundational overview that explains the core concepts behind modern AI.
- How Artificial Intelligence Works — a simple explanation of how AI learns, predicts, and improves through feedback loops.
- Machine Learning vs Artificial Intelligence — a clear breakdown of how ML fits inside the broader AI landscape.
- Neural Networks Explained — a beginner-friendly guide to layers, weights, and activations.
- Deep Learning Explained — the architecture that powers modern multimodal AI.
- How Transformers Work — an intuitive walkthrough of attention, tokens, and modern transformer stacks.
- How AI Works in Real Life — practical examples across business, healthcare, and daily technology.
For broader exploration beyond this cluster, visit the AI Guides Hub, check real-world model benchmarks inside the AI Tools Hub, or follow the latest model releases and updates inside the AI News Hub.